Fine-Tuning Qwen 2.5-72B for YouTube Content Generation: A Two-Step Training Approach
Large Language Models (LLMs) have revolutionized content generation, but getting them to perform well on domain-specific tasks often requires fine-tuning. Over the past few months, I've been experimenting with fine-tuning Qwen 2.5-72B for YouTube content generation, specifically focusing on two different training approaches: a sophisticated two-step process combining Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), and a simpler single-step SFT approach.
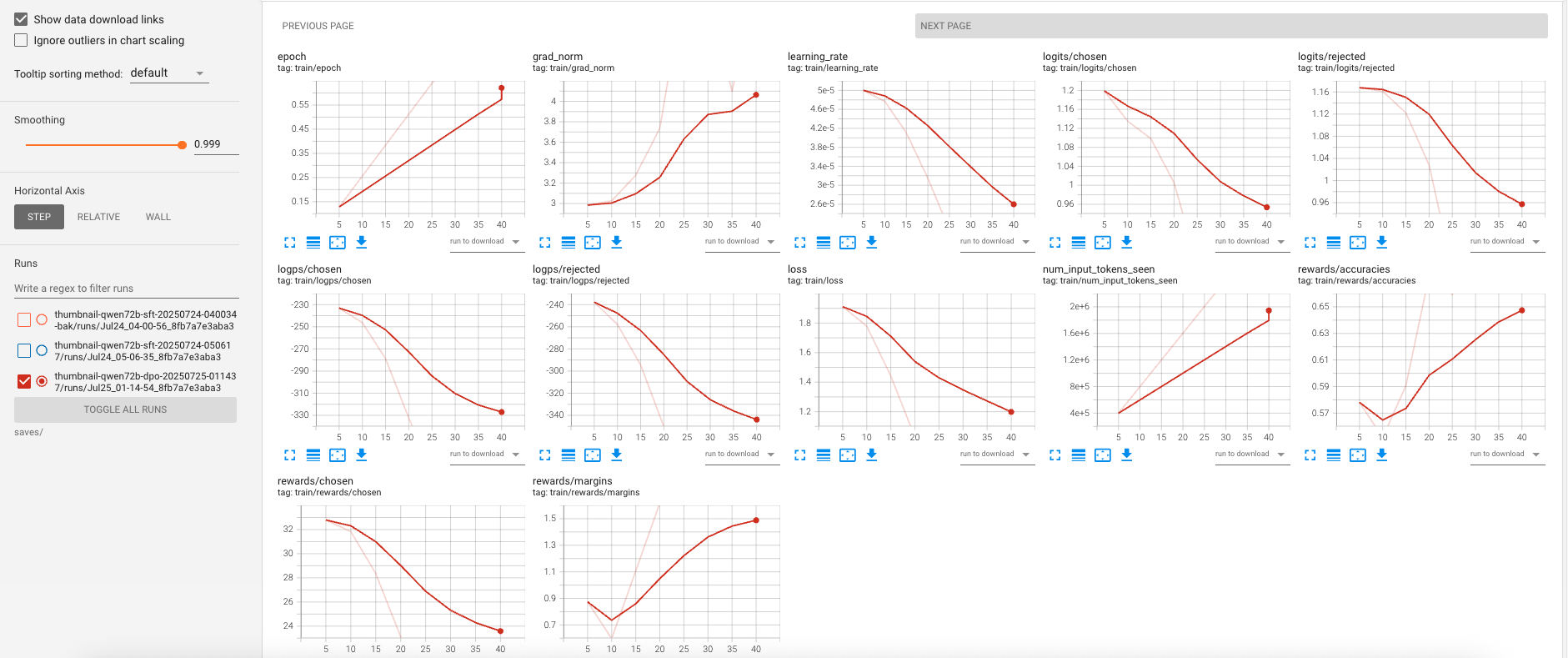
Figure: DPO run — preference loss decreases smoothly; the lower learning rate (5e-5) and 10% warmup reduce oscillations compared to SFT.
The Challenge
Training large models like Qwen 2.5-72B (with 72 billion parameters) presents several technical challenges:
- Memory constraints - The model is too large to fit on a single GPU
- Training efficiency - Need to minimize training time while maintaining quality
- Data quality - Ensuring the training data leads to meaningful improvements
- Optimization strategy - Choosing the right approach for different use cases
Technical Setup
Both training approaches used the same foundational setup:
- Base Model: Qwen 2.5-72B-Instruct
- Training Framework: LLaMA-Factory CLI
- Distributed Training: DeepSpeed with 8 GPUs (CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7)
- Parameter Efficiency: LoRA (Low-Rank Adaptation) with rank 16, alpha 32, dropout 0.1
- Precision: Mixed precision training (FP16/BF16)
Hardware Configuration
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export OMP_NUM_THREADS=8
Approach 1: Two-Step Training (Thumbnail Generation)
For the more complex thumbnail generation task, I implemented a two-step training process:
Step 1: Supervised Fine-Tuning (SFT)
The first phase focused on teaching the model the basic task through supervised learning:
Training Parameters:
- Epochs: 2.0
- Learning Rate: 0.0003
- Max Samples: 15,000
- Batch Size: 1 per device, 32 gradient accumulation steps
- Sequence Length: 512 tokens
- DeepSpeed: Stage 3 (CPU offloading for parameters and optimizer)
Key Configuration Details:
--stage sft \
--model_name_or_path Qwen/Qwen2.5-72B-Instruct \
--finetuning_type lora \
--lora_rank 16 \
--lora_alpha 32 \
--lora_dropout 0.1 \
--learning_rate 0.0003 \
--num_train_epochs 2.0 \
--max_samples 15000
The DeepSpeed Stage 3 configuration enabled training the 72B model by offloading parameters and optimizer states to CPU:
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
}
}
}
What actually happened in SFT (results)
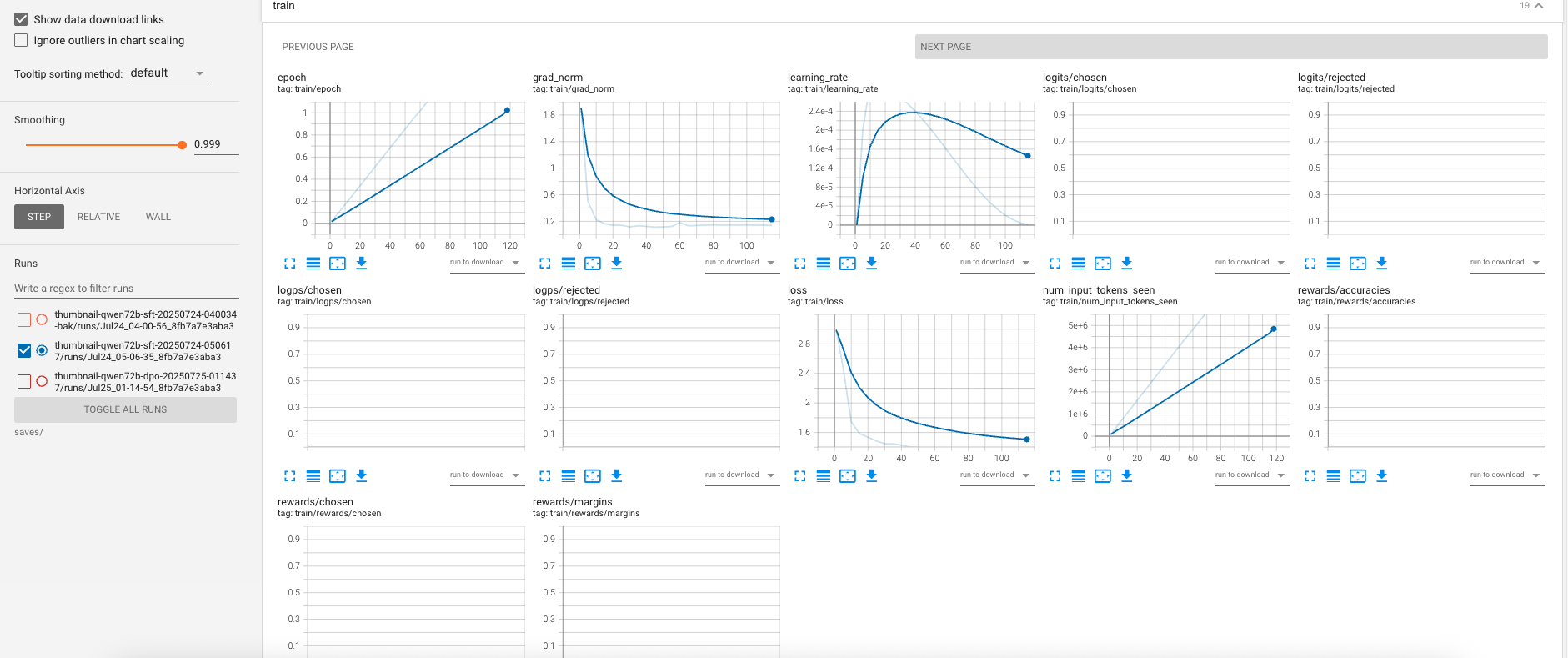
Figure: SFT run — the training loss trends downward with a smooth early warmup ramp from the cosine schedule; no instability spikes observed during the first 5% warmup.
Figure: SFT long-horizon view — loss continues to decline with small, expected oscillations; gradient accumulation of 32 keeps step-to-step variance modest while maintaining utilization.
- The SFT phase converged steadily: a quick initial drop then a slower, consistent descent.
- The cosine schedule with 5% warmup shows the expected gentle ramp before reaching the 0.0003 peak learning rate.
- With DeepSpeed Stage 3 offloading, step time is a bit higher than purely GPU-resident training but enables the 72B model to train reliably.
Step 2: Direct Preference Optimization (DPO)
After SFT, I applied DPO to align the model with human preferences:
Training Parameters:
- Epochs: 1.0
- Learning Rate: 0.00005 (significantly lower than SFT)
- Max Samples: 10,000
- Batch Size: 1 per device, 8 gradient accumulation steps
- Sequence Length: 1024 tokens (longer than SFT)
- DPO Beta: 0.1
- DeepSpeed: Stage 2 (less aggressive than SFT)
Key DPO Configuration:
--stage dpo \
--adapter_name_or_path saves/thumbnail-qwen72b-sft-20250724-050617 \
--create_new_adapter True \
--learning_rate 0.00005 \
--dpo_beta 0.1 \
--dpo_loss_type sigmoid
The DPO stage builds directly on the SFT checkpoint, creating a new adapter while loading the previously trained LoRA weights. This approach allows the model to learn from preference data (chosen vs. rejected responses) rather than just supervised examples.
What actually happened in DPO (results)
Figure: DPO run — preference loss decreases smoothly; the lower learning rate (5e-5) and 10% warmup reduce oscillations compared to SFT.
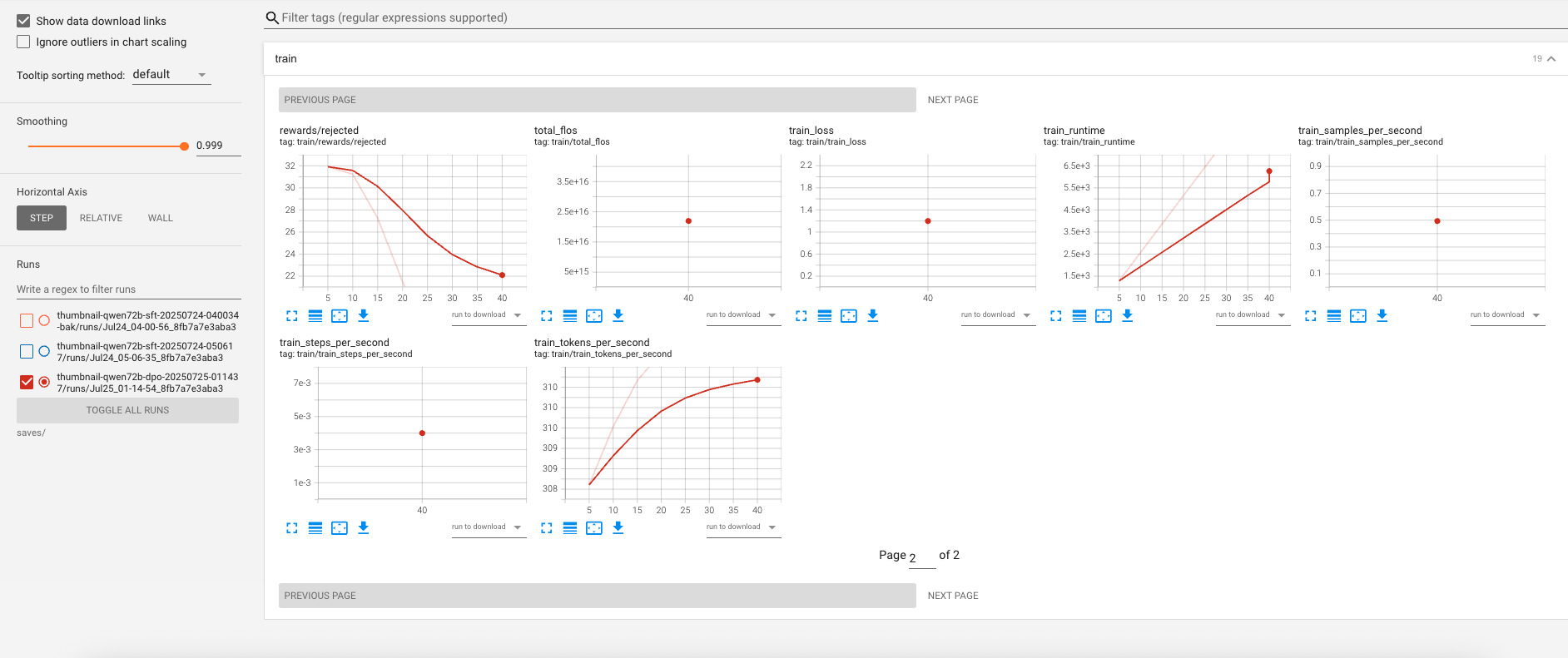
Figure: DPO extended view — training remains stable with smaller variance; Stage 2 configuration trades a little memory for faster steps than Stage 3.
- DPO fine-tunes behavior: the objective is preference-oriented, so improvements reflect better adherence to chosen vs. rejected pairs rather than raw cross-entropy.
- Lower learning rate and shorter run (1 epoch) produce controlled, incremental alignment on top of SFT without overfitting.
- Compared to SFT, the run shows tighter variance and a quicker time-to-signal, consistent with starting from a competent SFT adapter.
Approach 2: Single-Step SFT (Content Generation)
For the second use case, I used a simpler but more intensive single-step approach:
Training Parameters:
- Epochs: 5.0 (more than thumbnail training)
- Learning Rate: 0.0005 (higher than thumbnail SFT)
- Max Samples: 800 (much smaller dataset)
- Batch Size: 1 per device, 32 gradient accumulation steps
- Sequence Length: 512 tokens
- Precision: BF16 (instead of FP16)
The smaller dataset size (800 vs 15,000 samples) required more epochs and a higher learning rate to achieve good performance. The use of BF16 instead of FP16 provided better numerical stability for this specific training run.
Technical Insights
Memory Management
DeepSpeed proved essential for training 72B parameter models. The Stage 3 configuration for SFT enabled:
- Parameter offloading to CPU during SFT
- Optimizer state offloading
- Gradient partitioning across GPUs
For DPO, Stage 2 was sufficient since we were building on an existing adapter, requiring less memory overhead.
Learning Rate Scheduling
The cosine learning rate scheduler with warmup ratios proved effective:
- SFT: 5% warmup ratio with 0.0003 peak learning rate
- DPO: 10% warmup ratio with 0.00005 peak learning rate
- Single SFT: 10% warmup ratio with 0.0005 peak learning rate
LoRA Configuration Impact
The LoRA configuration (rank 16, alpha 32) provided a good balance between parameter efficiency and expressiveness. With lora_target all, we targeted all linear layers in the transformer, maximizing the model's ability to adapt while keeping the parameter count manageable.
Results and Observations
Two-Step Training Benefits
The SFT → DPO approach showed clear advantages for complex content generation tasks:
- SFT Phase: Established basic task competency and domain knowledge
- DPO Phase: Refined outputs to match human preferences and style guidelines
The longer sequence length in DPO (1024 vs 512 tokens) allowed the model to consider more context when making preference-based decisions.
Single-Step Training Efficiency
For simpler tasks with smaller datasets, the intensive single-step approach proved more efficient:
- Faster iteration cycles (no need to wait for SFT completion)
- Simpler hyperparameter tuning
- Good results with focused, high-quality datasets
In the single-step SFT setting described above (800 samples, BF16, higher learning rate and more epochs), convergence felt faster and more responsive to hyperparameter changes. While it lacks the additional polish provided by a preference step, it remains an excellent approach when data is focused and iteration speed matters.
Practical Considerations
Training Time
- Two-step approach: ~6-8 hours total (4-5 hours SFT + 2-3 hours DPO)
- Single-step approach: ~3-4 hours
Resource Requirements
Both approaches required significant computational resources:
- 8x high-memory GPUs for distributed training
- Substantial CPU RAM for DeepSpeed Stage 3 offloading
- Fast storage for dataset loading and checkpoint saving
Dataset Quality
The quality of training data proved more important than quantity. The 800-sample dataset for single-step training, when carefully curated, achieved comparable results to larger datasets in the two-step approach.
Conclusion
Fine-tuning Qwen 2.5-72B for YouTube content generation demonstrated that different tasks benefit from different training approaches:
Use two-step SFT → DPO when:
- You have access to preference data (chosen vs. rejected examples)
- The task requires nuanced understanding of quality and style
- You can afford longer training times
Use single-step SFT when:
- You have high-quality, focused training data
- The task is more straightforward
- You need faster iteration cycles
The key technical enablers were DeepSpeed for memory management, LoRA for parameter efficiency, and careful hyperparameter tuning based on dataset characteristics. These approaches make it feasible to fine-tune state-of-the-art models for specialized content generation tasks without requiring the resources of major AI labs.
Both approaches produced models capable of generating high-quality YouTube content, demonstrating that with the right technical setup and training strategy, even individual researchers can successfully fine-tune large language models for specialized applications.