Training DeepSeek V3 on 24× A100s — Part 7: Ray-Orchestrated Training (torchrun under Ray)
Use Ray to prep containers on each node, validate networking, then launch torchrun with DeepSpeed ZeRO-3 and a robust PEFT save patch.
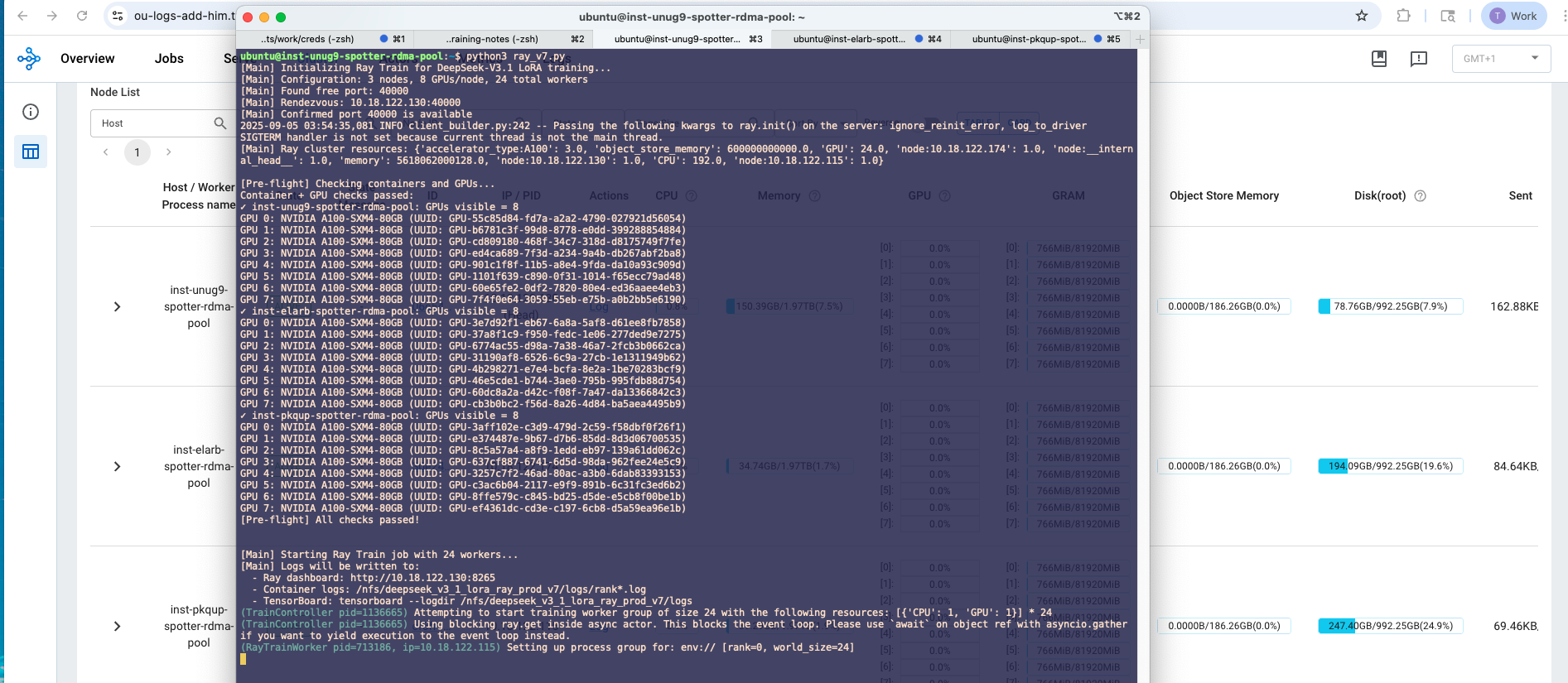
This post documents the Ray driver I use to orchestrate the same torchrun production setup across three nodes. Ray handles node pinning, container prep, rendezvous validation, and then runs the exact torchrun command we used in Part 2.
Overview
- Head and 2 workers (3 nodes total), 8 GPUs per node
- Ray used for orchestration only; multi-node DDP remains with
torchrun - Containers are recreated per run on each node, dependencies validated inside
- A one-proc DDP/NCCL probe runs first to validate rendezvous and NIC selection
Node prep inside each container
The script recreates the container and prepares the environment (trimmed):
docker run -d \
--name llamafactory \
--network host \
--gpus all \
--ipc host \
--shm-size=16g \
-v /nfs:/nfs \
-v /home/ubuntu/LLaMA-Factory:/app \
-v /home/ubuntu:/host_home \
--workdir /app \
hiyouga/llamafactory:latest \
sleep infinity
# Inside the container: basic tooling + pinned Transformers
pip install -U "tensorboard<3" tensorboardX
pip install -U "transformers==4.52.4"
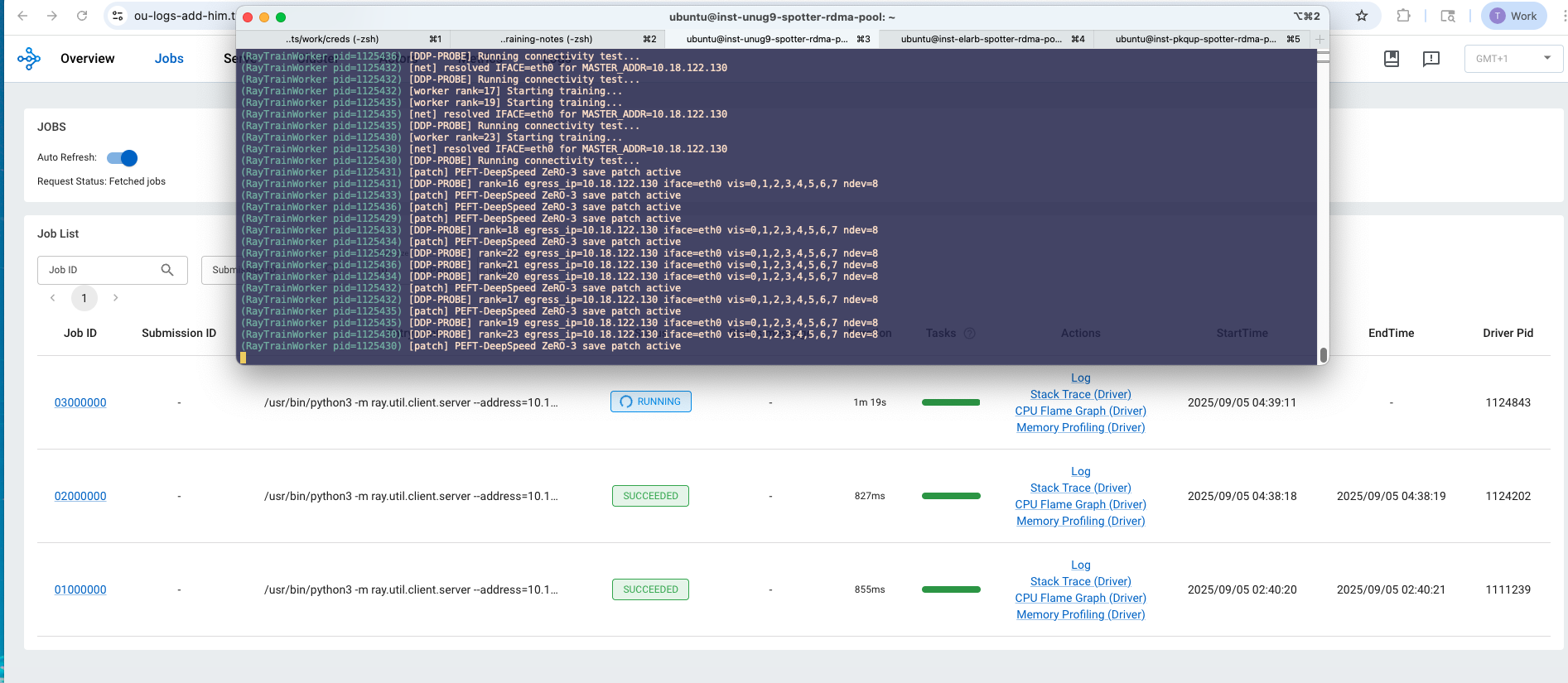
It also writes an Accelerate config (ZeRO-3) and a sitecustomize.py that patches Trainer.save_model so LoRA adapters are collected reliably under ZeRO-3. The patch gathers LoRA params with DeepSpeed when available, else falls back to PEFT:
from transformers import Trainer
from peft import get_peft_model_state_dict
from safetensors.torch import save_file
import torch, torch.distributed as dist, os
_orig = Trainer.save_model
def _patched(self, output_dir=None, _internal_call=True):
# ... detect LoRA params and gather via deepspeed.zero.GatheredParameters ...
# rank0 writes adapter_model.safetensors + adapter_config.json + debug info
# falls back to PEFT get_peft_model_state_dict if DeepSpeed gather not available
return
Trainer.save_model = _patched
Networking and NCCL environment
NIC selection is derived from routing to MASTER_ADDR, then conservative NCCL over TCP (IB/P2P/SHM disabled by default) and long timeouts:
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export CUDA_DEVICE_ORDER=PCI_BUS_ID
export LOCAL_WORLD_SIZE=8
export WORLD_SIZE=$(( NNODES * NPROC_PER_NODE ))
export MASTER_ADDR=10.18.122.130
export MASTER_PORT=39500
export NCCL_PORT_RANGE="${MASTER_PORT}-$((MASTER_PORT+31))"
export NCCL_SOCKET_IFNAME="$IFACE"
export GLOO_SOCKET_IFNAME="$IFACE"
export NCCL_SOCKET_FAMILY=AF_INET
export NCCL_IB_DISABLE=1
export NCCL_P2P_DISABLE=1
export NCCL_SHM_DISABLE=1
export NCCL_DEBUG=INFO
export TORCH_DISTRIBUTED_DEBUG=DETAIL
export TORCH_NCCL_BLOCKING_WAIT=1
export NCCL_TIMEOUT_MS=5400000
export TORCH_NCCL_TIMEOUT_MS=5400000
Before launching the full 8-proc job per node, the script runs a one-proc probe that initializes torch.distributed, performs an all_reduce, and prints success. This catches bad rendezvous or NIC issues early.
The actual training launch
The torchrun command mirrors Part 2, with ZeRO-3 and BF16:
torchrun \
--nnodes="$NNODES" \
--nproc_per_node="$NPROC_PER_NODE" \
--node_rank="$NODE_RANK" \
--master_addr="$MASTER_ADDR" \
--master_port="$MASTER_PORT" \
--max_restarts=0 \
src/train.py \
--stage sft \
--do_train \
--model_name_or_path /nfs/DeepSeek-V3-bf16 \
--dataset all_creator_training \
--template default \
--finetuning_type lora \
--preprocessing_num_workers 4 \
--overwrite_cache false \
--lora_target self_attn.q_a_proj,self_attn.q_b_proj,self_attn.kv_a_proj_with_mqa,self_attn.kv_b_proj,self_attn.o_proj \
--lora_rank 16 \
--lora_alpha 32 \
--output_dir "$OUTPUT_DIR" \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--learning_rate 1e-5 \
--adam_beta2 0.98 \
--weight_decay 0.01 \
--warmup_steps 100 \
--bf16 \
--deepspeed "$DS_CONFIG" \
--logging_steps 1 \
--save_strategy steps \
--save_steps 50 \
--save_on_each_node false \
--save_safetensors true \
--save_only_model true \
--max_steps 2000 \
--report_to tensorboard \
--logging_dir "$OUTPUT_DIR/logs"
Why this approach
- Reuses the known-good
torchrunflow while leveraging Ray for deterministic multi-node orchestration - Validates networking and rendezvous up front
- Ensures LoRA adapters are actually gathered and saved under ZeRO-3